近期,实验室硕士研究生段士童作为第一作者的论文“Negating Negatives: Alignment with Human Negative Samples via Distributional Dispreference Optimization”被Findings of EMNLP录用。该工作首先指出现有的有监督微调方法容易收到人类标注偏好数据集中噪声的影响,然后提出了仅仅使用人类标注的负样本实现对齐的任务。以此为目标设计了分布级别优化的D2O损失函数,并从理论证明该损失函数是实例级别优化DPO的上界。在多个开源模型上大量的实验表明,D2O在生成质量、减少有害性和信息丰富性方面与最新强基线相当或更优,并且具有更好的训练稳定性和更快的收敛速度。
期刊简介

EMNLP 2024(The 2024 Conference on Empirical Methods in Natural Language Processing)是全球自然语言处理领域的顶级学术会议之一,该会议由计算语言学协会(Association for Computational Linguistics,ACL)主办,主要集中于自然语言处理(NLP)的实证研究和方法,享有很高的学术影响力。该会议计划于2024年11月12日至11月16日在美国佛罗里达州迈阿密召开。
论文简介
Negating Negatives: 通过分布级优化利用人类标注负样本实现大语言模型对齐

论文链接:
https://arxiv.org/pdf/2403.03419
问题引入
大型语言模型(LLMs)在展示出强大的能力的同时,也带来了潜在的社会风险。为了确保LLMs的安全性,研究者们引入了对齐技术,以使其符合人类价值观,代其中代表的技术为基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)以及直接偏好优化(Direct Preference Optimization,DPO)。其中强化学习利用偏好模型建模人类偏好,通过强化学习来对齐大语言模型。DPO算法利用Bradley-Terry模型建模人类偏好,在不用外部显示偏好模型的情况下,利用语言模型隐式建模偏好。
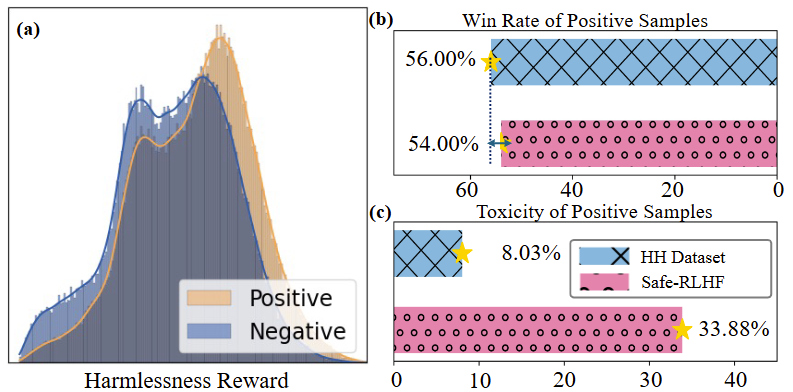
图 1 (a) HH数据集中正样本和负样本之间的差异很小。(b)利用GPT-4进行判断,正例的胜率较低。(c)数据集正例中存在一定比例的毒性样本
然而,现有的方法常常依赖于高质量的正负样本对。而这些样本通常是难以获得的,一方面,人工标注成本较高难以进行大规模标注;另一方面,图1中展示了我们对当前主流数据集进行的质量分析,结果显示人工标注的一致性较低,训练样本通常含有噪声。因此在本工作中,我们提出了一个新的对齐任务,即:仅仅通过人类标注的负样本,能否高效地实现对齐,在尽量减少模型有用性损失的情况下,尽可能降低模型的有害性。
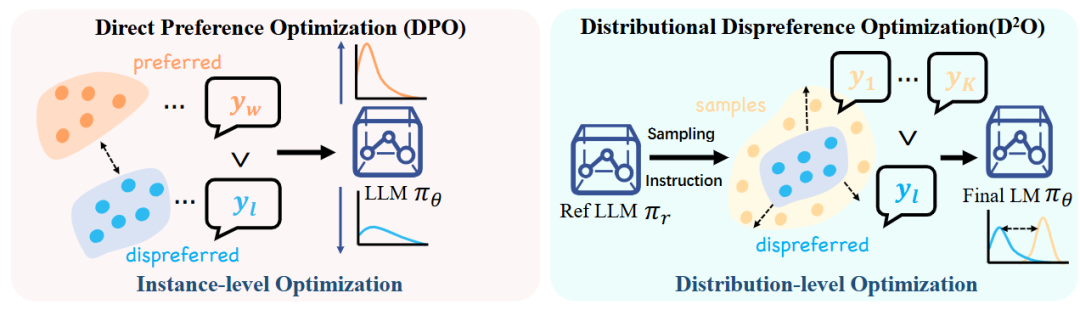
图2 DPO和D2O对齐流程对比
方法
实现上述目的一种方法是直接降低负样本输出的概率,但这样往往会导致模型的灾难性遗忘。
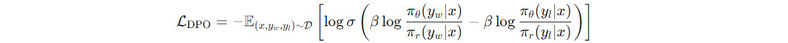
DPO成正负样本对优化的形式很好地避免了这个问题,然而这种从实例级别优化方式往往容易收到标注数据中噪声的影响。因此,本文首先引入了可控文本生成中的分布控制(Generation with Distributional Control,GDC)问题,它旨在从分布的角度控制模型的输出,如:要求模型输出内容中50%的内容涉及女性。基于此,我们定义了分布级别的偏好建模,并且推导出其建模出来的最优奖励函数和DPO中的是完全等价的,进而可以设计出以下的D2O损失函数:
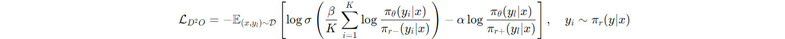
其中是待对齐的语言模型,为参考模型,相较于更加的有害。在具体操作过程中,我们先用初始模型针对每个负样本,生成多个合成的正样本。然后,利用上述损失函数进行优化,其中和以不同频率进行更新,每次更新以指数移动平均的形式进行。此外,我们在训练过程中,引入在线采样的合成正样本,进一步提升对齐效果。
实验
实验部分使用了PKU-SafeRLHF数据集进行评估,采用Alpaca-7b、Phi-3-4k-mini-instruct、Qwen2-1.5B三个不同大小的开源模型进行训练。对比方法方面,选取了主流的6种基于有监督微调的方法进行对比。在评估的指标方面,我们从多角度采用了多种评估的方法,首先,我们从无害性、有用性两个维度选取了4个主流的奖励模型给模型输出内容进行打分;使用了GPT-4评判模型生成内容相较于原始生成内容的胜率;以及采用MMLU评估对齐税的大小。
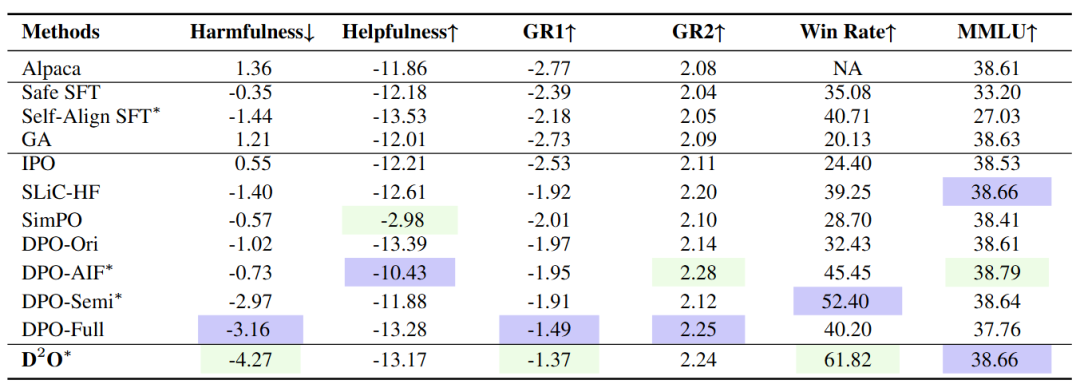
表1 Alpaca-7B实验结果
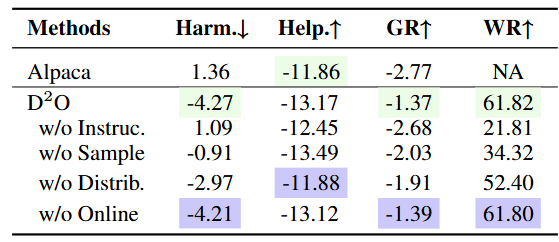
表2 消融实验结果
自动化评估的实验结果表明,D2O在减少有害性、保持有帮助性、提高训练稳定性和加快收敛速度方面均优于其他基线方法。此外,我们还进行了人工评估,以评估Alpaca、DPO和D2O生成的响应的无害性和有帮助性,结果进一步验证了D2O的有效性。在消融实验中,我们对于D2O的多个变体进行了对比,结果显示使用self-correction、分布级别优化和在线采样,有利于性能的提升。
分析
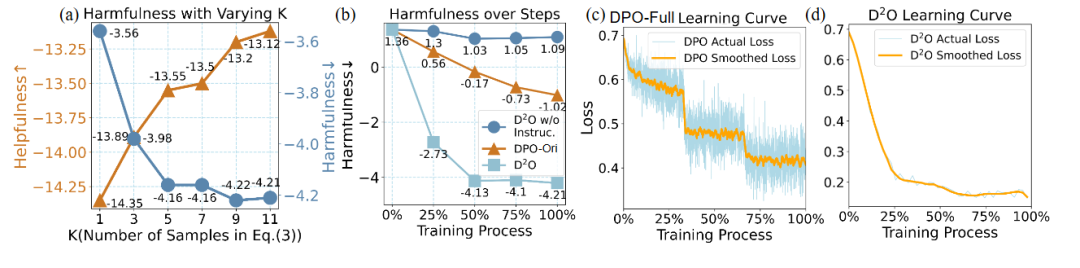
图3 (a):在采用不同数量合成正样本是有害性和有用性的变化。(b): 随着训练进行模型有害性的变化。(c)和(d): 训练过程中损失函数的变化。
我们进一步探究了训练中采用的正样本的数量的影响和以及训练过程中体现的性质。在引入更多的合成正样本时,模型的有害性不断下降,同时模型的有用性不断提升,说明引入更多的正样本能够减轻对齐税。同时,我们还可以观察到,在训练过程中,D2O的有害性下降将对于DPO更快,同时损失函数的下降更加的平滑,这体现了采用分布级别优化的优点。
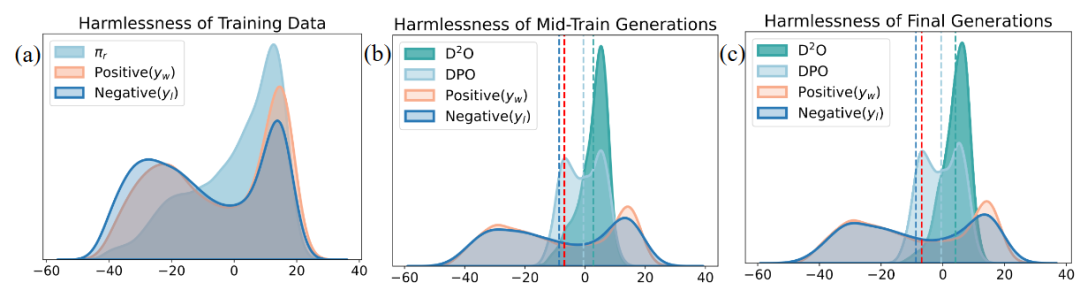
图4 训练不同阶段模型生成文本奖励分数的分布变化
此外,我们还进一步分析了训练的不同阶段,模型生成内容的奖励分布变化。可以观察到,相比于D2O, DPO对应的奖励分布具有明显的双峰特性,说明其在优化过程中受到了数据中噪声的影响,而D2O具有明显的单峰特性,且平均奖励有着明显的提升。
总结
本工作提出了使用人类标注的负面样本来实现对齐的任务,并据此导出了分布级偏好优化的损失函数D2O,有效地减少了有害性,同时保持了有用性。实验结果表明,D2O在减少有害性、保持有用性、提高训练稳定性和加快收敛速度方面均优于其他基线方法。未来的工作将探索将D2O方法扩展到显式奖励建模和RLHF,并进一步减少大语言模型的对齐税。
作者信息
如果您对本文内容感兴趣的话,可以与作者联系:
段士童 复旦大学计算机学院协同信息与系统实验室 硕士研究生
研究方向:大语言模型价值观对齐
联系方式:stduan22@m.fudan.edu.cn