近期,实验室博士生李亚琼作为第一作者的论文“‘Harmless to You, Hurtful to Me!’: Investigating the Detection of Toxic Languages Grounded in the Perspective of Youth”被The 20th International AAAI Conference on Web and Social Media (ICWSM 2026) 会议录用。
该文章聚焦青少年如何感知社交媒体毒性内容的研究问题,尽管先前的研究对社交媒体中的毒性检测进行了广泛研究,但风险感知是主观的,与成年人判断毒性相比,当前研究对青少年是否具有不同的毒性感知被忽视了,即那些被成年人认为无毒但青少年认为有毒的语言(统一称为“Youth-toxicity”)。我们以中国青少年为研究对象,构建了第一个中国““Youth-toxicity”数据集,并进行了广泛分析。结果表明,青少年对毒性内容的感知与多种因素有关,包括内容来源以及与文本相关的元属性等。将这些元信息纳入主流毒性检测方法可显着提高针对青少年毒性检测的准确性。
会议简介

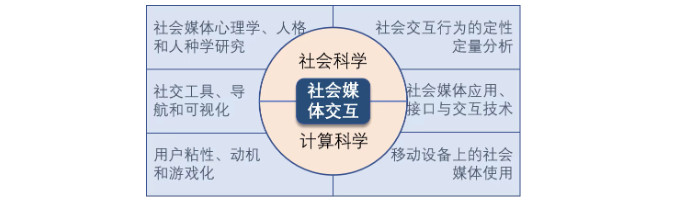
ICWSM (The International AAAI Conference on Web and Social Media) 是由AAAI于2007年创立,人机交互领域具有重要影响力的国际学术会议。会议强调结合社会科学和计算科学方法来研究社会媒体中的个体与群体行为,研究主题涵盖社会媒体心理学、人格和人种学研究,社会交互行为的定性定量分析,社交工具、导航和可视化,社会媒体应用、接口与交互技术等。
ICWSM每年投稿量逾300篇,约有20%被接收发表(长文),投稿者来自斯坦福大学、密歇根大学、普林斯顿大学、康奈尔大学、牛津大学等高校,Google、Microsoft、IBM等著名研究机构。
论文简介

论文链接:https://arxiv.org/pdf/2508.02094
青少年作为数字时代的原住民,一直是在线平台的狂热群体。然而,社交媒体中产生了大量的毒性内容(即“粗鲁的、不尊重他人的、或者是不合理的内容,可能会导致某人离开讨论”),如仇恨语言、冒犯语言、欺凌侮辱等,对于处于认知发展敏感时期的青少年而言,这些毒性内容具有极大的风险[7],容易造成青少年心理抑郁、饮食失调、自残等健康问题。
风险认知是一个高度主观的概念,青少年对于毒性内容的理解与非青少年用户的理解存在较大差异[。正如Marwick等人提出,那些成年人被称之为欺凌的语言,青少年更倾向于将其引发的小冲突或者数字痕迹称之为“戏谑”;成年人认为是“无害”的语言,可能对青少年造成的伤害更大。尽管之前的研究已经针对毒性数据和行为开展了大量的实证研究和模型设计,但并没有从青少年的特殊视角进行深入探究,尤其是非青少年认为是无毒而青少年视为有毒的内容(“youth-toxicity”)。考虑青少年与其他非青少年用户对毒性内容的理解差异至关重要,因为现有的毒性检测模型或应用设计的原则普遍来源于成年人或第三方等非青少年视角的毒性标准,而不是青少年。为了弥补这一空白,本文试图探究如下两个研究问题:
1) RQ1:社交媒体中的“youth-toxicity”内容具有什么特点?
2) RQ2:现在的毒性检测技术能否精准识别出“youth-toxicity”内容?
对上述问题的探究面临多方面的挑战。首先,目前已有公开的毒性数据并非从青少年视角标注,这些数据集难以充分代表青少年的认知,这就要求本研究要以青少年的视角标注大量的数据,费时费力;其次,HCI和AI领域关于毒性的研究涉及广泛的毒性类别,包括仇恨语言、冒犯语言、欺凌侮辱等,这些语言中可能包含一些“youth-toxicity”语言,尚不清楚哪些类别对青少年来说是重要的,加剧了数据标注的工作量和难度。
针对上述挑战,本文开展了两阶段的研究。针对RQ1,我们设计了一个面向青少年的毒性标注项目YouthLens,招募了66名13~21岁的青少年参与了为期15日的标注过程(未成年人需征得家长同意方能参与标注),最终获得了5092条“youth-toxicity”语言,包括毒性标签、话语来源、毒性类型(类型来自文献系统综述)和毒性风险等内容。为了回答RQ2,我们采用了三种具有代表性的毒性检测方法,包括Perspective API、预训练模型(MeteHateBERT、RoBERTa等)、大语言模型(GPT-4o、Llama-3.1、GLM-4、Qwen2.5)。这些方法涉及发布模式(开源和闭源)、模型大小、不同的语言。
通过上述详细的分析,我们获得了几项发现。在RQ1中,诸如青少年属性(年龄和性别)和文本相关特征(话语来源、文本长度和LIWC语义)等元信息是影响青少年对“youth-toxicity”语言感知的关键因素。研究发现,青少年对来自家人、另一半或朋友的语言比来自陌生人的语言更宽容,而当“youth-toxicity”话语真的来自这些熟人,尤其是家庭成员时,他们往往会认为这些话语风险更高。研究还表明,年龄较大的青少年和女性青少年更有可能将话语视为“youth-toxicity”,对不同的毒性类型更敏感,更倾向于将其视为更高的风险水平。此外,一些语义特征,如与自我认同和生理行为相关的特定词语,增加了话语被认为是“youth-toxicity”的可能性。对于RQ2,与传统方法相比,大语言模型在不同的“youth-toxicity”检测任务中显示出其潜力,特别是在向其提供相关元信息时。然而,引入它们也会带来负面影响,比如在“youth-toxicity”判断中夸大风险。此外,微调可以进一步提高大语言的检测性能,而few-shot学习技术带来的收益有限。
数据收集和实验方法
Youth-toxicity”数据收集流程如下:
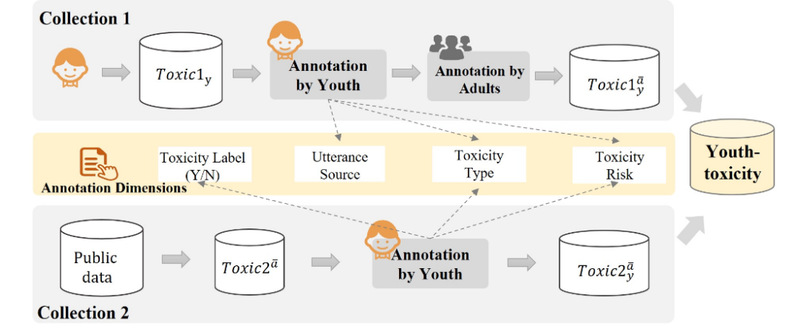
图表1 “Youth-toxicity”语言收集流程
本文设计开发了一个基于网络的安全程序YouthLens,旨在收集青少年视为有毒而非青少年认为是无毒的内容。YouthLens主要包含两项流程:青少年贡献在线经历中认为的Toxic数据以及青少年标注公开数据集中的无毒数据,如图所示。对于第一项流程,我们鼓励青少年能够主动贡献自己曾经看到或者经历过的网络毒性内容,并对其进行标注;然而,在有限时间内,青少年标注者可能难以准确回忆起所有的毒性语言经历,导致贡献毒性数据类型不完整。为此增加了第二项流程,青少年被要求标注社交媒体的公开无毒数据。其次,我们对“youth-toxicity”数据进行了详细分析。首先,采用逻辑回归方法对数据进行特征分析,以探索青少年感知毒性内容的相关因素。然后,使用现有毒性检测技术对这些“youth-toxicity”内容进行检测,包括Perspective API、预训练模型、大语言模型。此外,设计了三种提示辅助大语言模型检测,分别是直接提示(通过给出检测角色、话语、任务描述和输出格式,要求提供检测结果)、目标提示(除上述信息外,提供目标人群信息以获得检测结果)、基于元信息的提升(告诉大语言模型与毒性因素相关的元信息,如目标属性和文本相关的特征,要求提供检测结果)
“Youth-toxicity”语言特征分析
就青少年属性而言,如下表所示,年龄较大的青少年和女性青少年更有可能将这些语言视为“youth-toxicity”,对其类型更敏感,并将其视为具有更高的风险。相反,年龄较小的男性青少年则倾向于将“youth-toxicity”视为低风险的“冒犯语言”。在语言来源方面,青少年对家人、另一半和朋友等非陌生人的语言表现出更高容忍度,即这些语言不太可能被视为毒性。然而,当来自这些来源的话语已经被青少年认为是“youth-toxicity”时,风险性更高,而且来自家庭成员的语言更有可能被视为“高风险”威胁。此外,较短的文本更容易被视为“youth-toxicity”,青少年对个人代词(“你”和“她/他”)、社会关系(“家庭”、“朋友”和“人类”)、生理行为(“性”和“身体”)以及特殊术语(“否定”和“填充”)等特定词汇更为敏感。涉及性话题的讨论更容易被视为高风险。
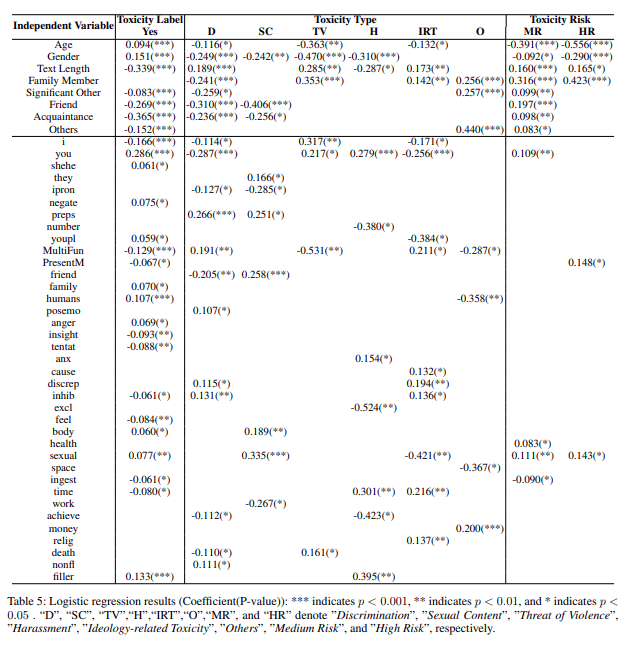
图表2 逻辑回归结果
“Youth-toxicity”语言检测结果分析
传统毒性检测方法在“youth-toxicity”语言检测中表现不佳,相比之下,大语言模型在检测“youth-toxicity”方面表现出不同的显著改善,尤其是向大语言模型提供“youth-toxicity”语言涉及的目标信息和元信息能够显著提升毒性标签预测和毒性类型分类的性能。其次,与基于目标的提示方法相比,基于元信息的提示方法能够为大语言模型检测带来更高的效益。然而,它也带来了一些负面影响,体现在对低风险毒性样例的误判上。与此同事,微调技术可以进一步提高大语言模型在毒性检测各个任务上的性能,但是Few-shot技术带来的收益有限,具体参考如下图表内容。

图表3 基线模型性能
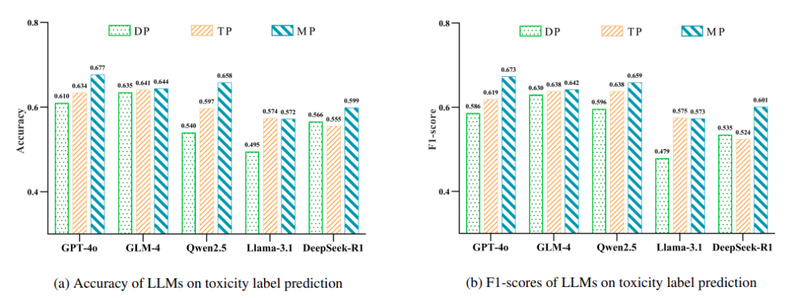
图表4 大语言模型在毒性标签预测任务上的性能表现(其中DP代表使用直接提示,TP代表使用目标提示,MP代表使用基于元信息的提示)
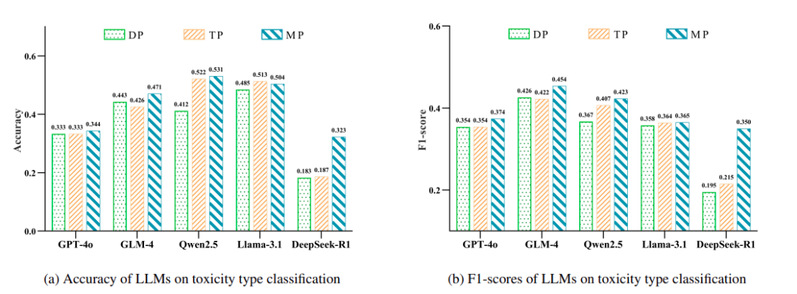
图表5 大语言模型在毒性类型分类任务上的性能表现
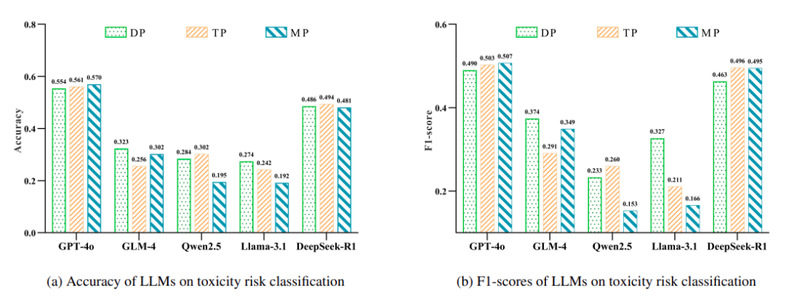
图表6 大语言模型在毒性风险分类任务上的性能表现
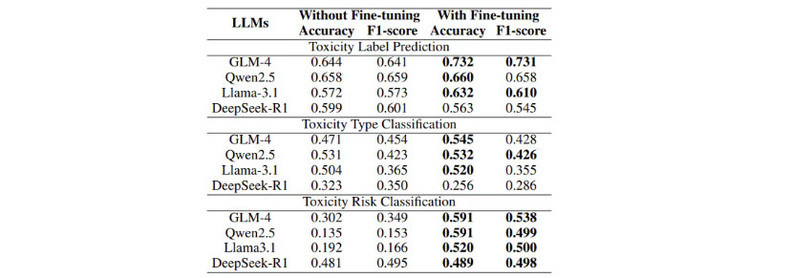
图表7 基于元信息的提示条件下,是否对大语言模型进行微调的性能表现
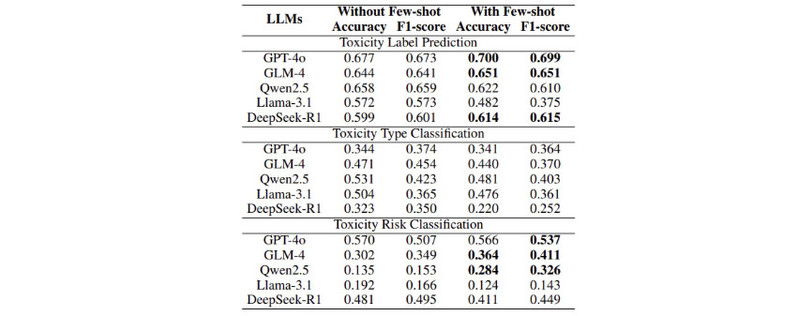
图表8 基于元信息的提示条件下,大语言模型是否采用Few-shot技术的性能表现
小结
本研究中,我们深入研究了“youth-toxicity”语言并分析相关特征,并且评估了当前主流的毒性检测方法在识别“youth-toxicity”语言的有效性。我们发现元信息,如用户属性(年龄和性别)和文本相关的特征(语言来源、文本长度和LIWC语义),是青少年感知“youth-toxicity”语言的关键因素。此外,GPT-4o和GLM-4等先进的大语言模型在“youth-toxicity”语言的毒性标签预测、毒性类型分类、毒性风险分类等多个任务中表现出了它们的潜力,尤其是告知大语言模型相关的元信息时。这些发现为未来针对以青少年为中心的毒性检测设计提供了一些新的见解。
如果您对本文内容感兴趣,可与通讯作者联系: zhangpeng_@fudan.edu.cn