日前,实验室博士生韩明哲作为第一作者的论文“FedCIA: Federated Collaborative Information Aggregation for Privacy-Preserving Recommendation”被The ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR) 会议录用。
高效的用户信息隐私保护共享是提升可信人智协同推荐性能的关键。论文提出了一种全新的聚合范式,聚焦于捕捉人类用户间的协同信息,突破了传统联邦学习对于参数的高度依赖,通过严格的理论分析与证明、全面综合的实验,充分验证了FedCIA的有效性和高效性,为可信人智协同推荐提供了创新思路和坚实基础。
会议简介

The ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)会议是信息检索领域的顶级学术会议,由国际计算机学会(ACM)主办,是中国计算机学会推荐的A类国际学术会议。该会议聚焦信息检索(IR)领域的前沿理论与技术,涵盖用户行为分析、搜索算法、推荐系统等方向,具有全球学术与产业影响力。该会议计划于2025年7月13日至18日在意大利帕多瓦召开。
论文简介
FedCIA:利用协同信息聚合的联邦推荐系统

论文链接:https://arxiv.org/html/2504.14208v1
现有的联邦推荐系统通常遵循一个统一的范式。每个客户端根据自身数据训练各自的推荐模型,随后在聚合步骤中将embedding参数分为用户和物品两部分,其中用户参数因为包含了用户隐私被客户端保存在本地,物品参数则会被上传并聚合在中央服务器上,聚合后的物品参数被分发回客户端,用于下一轮训练。这种方法将不同的用户模型对齐到一个参数空间中,使客户端能够更有效利用全局信息进行推荐。
虽然这种聚合方案效果显著,并被广泛利用在各种联邦推荐系统中,但其存在着潜在的问题。首先,这种聚合方案大多是通过参数求和方式完成的,当某一物品在两个客户端分布完全相反时,他们的分布会因为求和而被抵消,造成信息丢失。其次,这种聚合方案让所有的客户端的物品都处于同一分布下,但种分布不是对于每一个客户端都是最优的,影响了个性化用户建模。最后,这种方案要去客户端模型参数,特别是物品embedding维度一致,缺乏可扩展性。
我们认为,这些问题的根本原因在于联邦学习聚合方法对推荐系统中模型参数的过度依赖。为了解决这一问题,我们重新思考了推荐系统模型的本质,我们注意到,近年来深度学习的优越表现鼓励研究人员用复杂的网络参数化用户和物品,却忽视了推荐系统中起到根本作用的协同信息,即用户与物品的相似度。基于这一发现,当联邦学习框架中参数聚合中存在限制时,重新考虑协同信息的重要性变得至关重要。
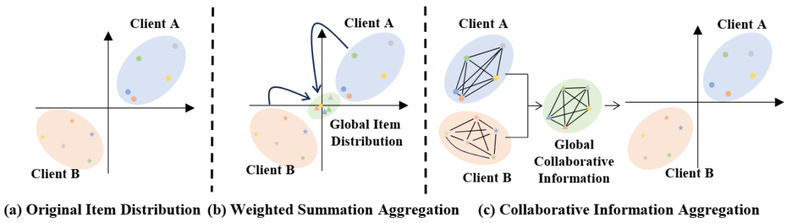
图 1 联邦推荐系统中的两种聚合范式
基于这一思想,我们提出一种新的范式:协同信息聚合范式。如图1所示,图1(a)表示了各个客户端在聚合前的分布,图1(b)表示了现有联邦学习基于参数的聚合方案,其将参数强行映射到了一个空间,因此存在上述问题,而我们提出了全新的范式(图1(c)),让物品协同信息在各个客户端保持一致,且不强行更改其分布。
协同信息聚合
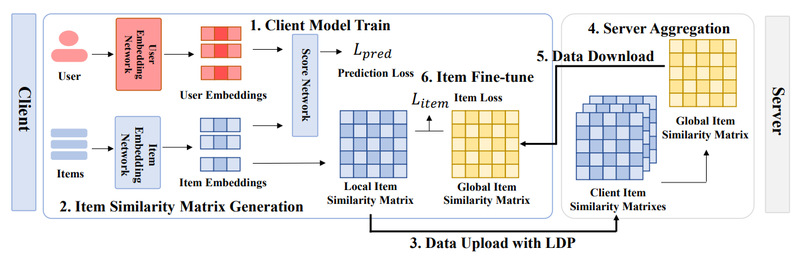
图 2 FedCIA的基本架构
如图2所示,我们提出了FedCIA,一种联邦协同信息聚合框架。与传统联邦推荐系统不同,该方法不再上传物品的embedding参数,而是对参数进行两两点乘,计算其全局物品相似度矩阵,并上传该矩阵进行聚合。聚合后的相似度矩阵无法直接部署在客户端模型中,因此客户端模型根据全局相似度矩阵进行微调来近似全局协同信息。
理论分析
直觉上来说,聚合协同信息是一个有效的联邦推荐方法,但其缺乏相关的理论证明。因此我们基于图信号处理理论,对协同信息聚合进行了分析。我们假设两个场景,第一个场景下,用户并不关注自身的隐私,并将交互数据直接上传到服务器进行推荐。
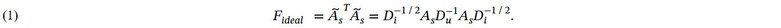
第二个场景下,用户关注自身的隐私,并各自训练推荐模型后进行协同信息聚合。
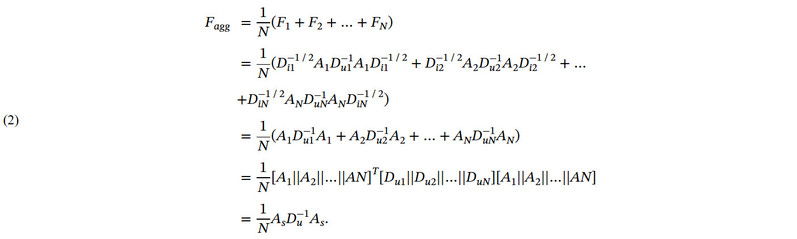
我们分析了这两个场景下的推荐模型,并注意到在不考虑物品的全局流行度的前提下,这两个场景的推荐模型完全一致。
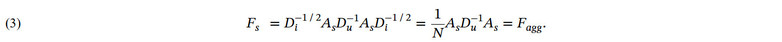
这说明对协同信息的聚合可以近似于直接使用全局隐私信息进行训练,进而展现了协同信息聚合的有效性。
实验
表1 FedCIA实验结果
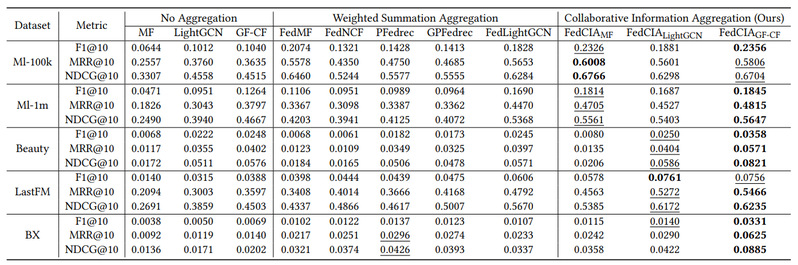
我们在5个常用推荐数据集上进行试验,结果如表1所示。可以注意到,由于我们的方法保留了模型的个性化信息,因此效果均优于现有的联邦推荐系统方法。
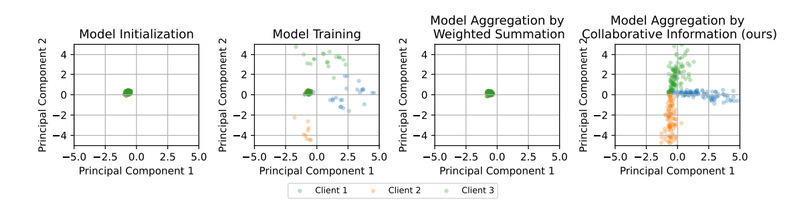
图3 不同范式下物品参数的分布
我们统计了我们的方法与传统联邦推荐系统方法的物品参数分布,如图3所示。可以注意到,我们的方法在不同客户端上有着不同的物品分布,这表明我们的方法可以更好地建模模型的个性化信息。
总结
本工作提出了全新的联邦推荐系统范式,该范式利用相似度聚合取代了参数聚合,因此有着更强大的个性化建模能力与可扩展性。试验结果表明,该范式由于现有的基于参数聚合的联邦推荐系统方法。
如果您对本文内容感兴趣,可与通讯作者联系: zhangpeng_@fudan.edu.cn